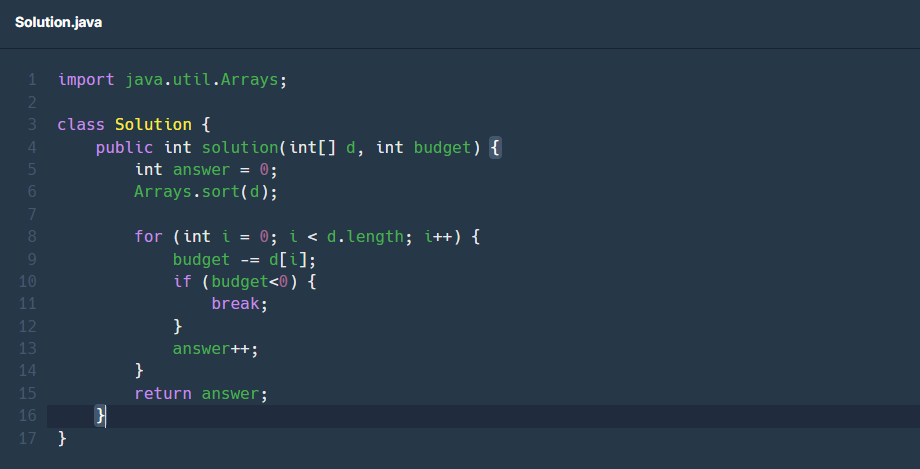
S사에서는 각 부서에 필요한 물품을 지원해 주기 위해 부서별로 물품을 구매하는데 필요한 금액을 조사했습니다. 그러나, 전체 예산이 정해져 있기 때문에 모든 부서의 물품을 구매해 줄 수는 없습니다. 그래서 최대한 많은 부서의 물품을 구매해 줄 수 있도록 하려고 합니다.
물품을 구매해 줄 때는 각 부서가 신청한 금액만큼을 모두 지원해 줘야 합니다. 예를 들어 1,000원을 신청한 부서에는 정확히 1,000원을 지원해야 하며, 1,000원보다 적은 금액을 지원해 줄 수는 없습니다.
부서별로 신청한 금액이 들어있는 배열 d와 예산 budget이 매개변수로 주어질 때, 최대 몇 개의 부서에 물품을 지원할 수 있는지 return 하도록 solution 함수를 완성해주세요.
제한사항
d는 부서별로 신청한 금액이 들어있는 배열이며, 길이(전체 부서의 개수)는 1 이상 100 이하입니다.
d의 각 원소는 부서별로 신청한 금액을 나타내며, 부서별 신청 금액은 1 이상 100,000 이하의 자연수입니다.
budget은 예산을 나타내며, 1 이상 10,000,000 이하의 자연수입니다.
입출력 예
입출력 예 설명
입출력 예 #1 각 부서에서 [1원, 3원, 2원, 5원, 4원]만큼의 금액을 신청했습니다. 만약에, 1원, 2원, 4원을 신청한 부서의 물품을 구매해주면 예산 9원에서 7원이 소비되어 2원이 남습니다. 항상 정확히 신청한 금액만큼 지원해 줘야 하므로 남은 2원으로 나머지 부서를 지원해 주지 않습니다. 위 방법 외에 3개 부서를 지원해 줄 방법들은 다음과 같습니다.
1원, 2원, 3원을 신청한 부서의 물품을 구매해주려면 6원이 필요합니다.
1원, 2원, 5원을 신청한 부서의 물품을 구매해주려면 8원이 필요합니다.
1원, 3원, 4원을 신청한 부서의 물품을 구매해주려면 8원이 필요합니다.
1원, 3원, 5원을 신청한 부서의 물품을 구매해주려면 9원이 필요합니다.
3개 부서보다 더 많은 부서의 물품을 구매해 줄 수는 없으므로 최대 3개 부서의 물품을 구매해 줄 수 있습니다.
입출력 예 #2 모든 부서의 물품을 구매해주면 10원이 됩니다. 따라서 최대 4개 부서의 물품을 구매해 줄 수 있습니다.
나의 예시 코드
여기서 핵심은 예산을 나눠주면서 마이너스 값이 나오기 전까지 계산해주며 남은 금액은 도출할 필요가 없다는 것입니다.
예를들어, testcase 1번 처럼
1원, 2원, 3원을 신청한 부서의 물품을 구매해주려면 6원이 필요합니다.
1원, 2원, 5원을 신청한 부서의 물품을 구매해주려면 8원이 필요합니다.
1원, 3원, 4원을 신청한 부서의 물품을 구매해주려면 8원이 필요합니다.
1원, 3원, 5원을 신청한 부서의 물품을 구매해주려면 9원이 필요합니다.
남은 금액은 각각 3원, 1원, 0원이지만 나눠줄 수 있는 최대 부서는 3개로 동일합니다. 따라서 남은 금액은 고려할 필요가 없습니다.
1. Runnable 인터페이스를 구현하여 Thread 생성자로 해당 구현체를 넘겨주는 방법
2. 직접 Thread 클래스를 상속하는 방법
Thread 클래스를 상속받으면, 다른 클래스를 상속받을 수 없기 때문에 Runnable 인터페이스를 구현하는 방법이 일반적이다. 또한, run() 메소드만 오버라이딩 할 경우라면 Runnable 인터페이스를 사용하고, Thread의 다른 메소드들을 오버라이딩 할 것이라면 Thread 클래스를 상속하는 방식을 택하면 된다.
몇 가지 다른 점이 존재하는데 Runnable 인터페이스를 구현한 경우, Runnable 인터페이스를 구현한 클래스의 인스턴스를 생성한 다음, 이 인스턴스를 Thread 클래스 생성자의 매개변수로 제공해야한다. Thread t2 = new Thread(new ThreadEx1_2());
또한, Thread 클래스를 상속받은경우, 자손 클래스에서 조상 클래스 Thread 클래스의 메소드를 직접 호출할 수 있지만, Runnable을 구현하면 Thread클래스의 static 메소드인 currentThread()를 호출하여 쓰레드에 대한 참조를 얻어와야 호출 가능하다.
Thread를 10개를 생성하고 각 Thread에서 5개의 숫자를 출력시키는 프로그램을 짜보았다.
public static void main(String[] args) { // TODO Auto-generated method stub Properties configs = new Properties(); configs.put("bootstrap.servers", "211.41.186.140:9092, 211.41.186.140:9093, 211.41.186.140:9094"); // kafka server host 및 port // bootstrap.servers 카프카 클러스터에 처음 연결을 하기 위한 호스트와 포트 정보로 구성된 리스트 configs.put("session.timeout.ms", "10000"); // session 설정 *(5초로 설정)* // 컨슈머와 브로커 사이의 세션타임 아웃 시간, 브로커가 살아있는것으로 판단하는 시간 configs.put("group.id", "tims-kafka"); // topic 설정 // 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자 configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // key deserializer configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // value deserializer //"key.deserializer", "value.deserializer" - 바이트로 표현된 Key, Value 값을 다시 객체로 만들어 주는 클래스 KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs); // consumer 생성 consumer.subscribe(Arrays.asList("spark")); // 이 설정들을 세팅한 Properties 객체를 인자로 넘겨서 KafkaConsumer 객체를 생성, topic 설정
while (true) { // 계속 loop를 돌면서 브로커에서 메시지를 읽어 들임 ConsumerRecords<String, String> records = consumer.poll(500); // 일정량의 ConsumerRecord 들이 담긴 ConsumerRecords 객체가 리턴 for (ConsumerRecord<String, String> record : records) { String s = record.topic(); if (s.equals("spark")) { System.out.println(record.value()); } else { throw new IllegalStateException("get message on topic " + record.topic()); } } } } }
public class Producer { public static void main(String[] args) { // TODO Auto-generated method stub Properties configs = new Properties(); configs.put("bootstrap.servers", "211.41.186.140:9092, 211.41.186.140:9093, 211.41.186.140:9094"); // 카프카 프로듀서가 최초로 접속할 때 필요한 주소들 configs.put("acks", "all"); // 자신이 보낸 메시지에 대해 카프카로부터 확인을 기다리지 않음, 속도가 가장 느리며 메시지 손실 가능성 없음
configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // serialize 설정 configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // serialize 설정 // 카프카 메시지의 키와 데이터 값를 바이트 배열로 만들어 줄 클래스를 명시한다. // org.apache.kafka.common.serialization 인터페이스를 구현한 클래스를 사용할 수 있다 KafkaProducer<String, String> producer = new KafkaProducer<String, String>(configs); // message를 생성 for (int i = 0; i < 5; i++) { String v = "hello"+i; ProducerRecord<String, String> record = new ProducerRecord<String, String>("spark", v); // 카프카 서버로 보낼 메시지 생성, ProducerRecord 생성자의 첫 번째 인자는 Topic 이름, 두 번째는 전송할 데이터 producer.send(record); } // 종료 producer.flush(); producer.close(); } }
: 버전 관리 시스템으로 방대한 소스코드를 공동으로 관리하기 위해 만들어진 시스템이며 버전관리, 백업, 협업을 위주로 한다.
버전 관리 - 수많은 파일들의 변경 사항 이력을 추적하고 관리할 수 있다.
백업 - 하드웨어는 언젠가는 손상되기 때문에 다른 공간에도 작업 파일을 보관해야한다.
협업 - 모두 다른 공간에 있어도 원격 저장소를 매개로 함께 작업을 동시에 진행할 수 있다.
GIT의 장점
소스코드를 주고 받을 필요 없이, 같은 파일을 여러명이 동시에 작업하는 병렬 개발이 가능하다.
브랜치를 통해 개발한 뒤, 본 프로그램에 합치는 방식으로 개발을 진행할 수 있다.
분산버전관리 이기 때문에 인터넷이 연결되지 않은 곳에서도 개발을 진행할 수 있으며, 중앙 저장소가 날라가도 다시 원상복구가 가능하다.
Local Repository는 내 컴퓨터의 내부 저장소를 의미하고, Remote Repository는 서버 등 네트워크 상의 원격 저장소를 의미한다. 기본적으로 로컬 저장소에서 작업을 진행하고 그 결과를 원격 저장소에 동기화 시킨다.
working directory : 버전으로 만들어지기 전 파일을 수정하는 곳 (작업트리라고도 한다.)
staging area : 버전관리를 원하는 파일을 모으는 곳
repository : 만들어진 버전들이 모인 곳, git으로 관리하고 있는 폴더
branch : 가지 또는 분기점, 여러 사람이 공통된 파일을 기반으로 서로 다른 작업을 병향해야 할 때 사용하는 기능
git add : 작업 트리에 존재하는 파일을 스테이지 영역으로 스테이징 시킴
git commit: 새로운 버전을 생성한다는 의미이고 하나의 버전에서 여러 종류의 파일을 함께 관리 할 수 있고, 어떠한 변경 사항이 있는지 커밋메시지를 남겨둠
git push : local 디렉토리로부터 원격저장소로 보냄
pit fetch & pull : pull 명령어는 원격 저장소의 소스를 가져오고 해당 소스가 현재 내 소스보다 최신 버전이라면 지금의 버전을 해당 소스에 맞춰 올리는 merge 작업을 하고, fetch 명령어는 단지 소스를 가져올 뿐 merge 작업은 하지 않음
git checkout: 작업 트리에 존재하는 파일의 수정한 내용을 checkout 명령어를 사용하여 취소 가능
git merge : 다른 branch의 내용을 현재 branch로 가져와 합치는 작업
GIT의 특징
Distributed development
: 전체 개발 이력을 각 개발자의 로컬로 복사본을 제공하고 변경된 이력을 다시 저장소로 복사한다. 이러한 변경은 추가개발지점을 가져와 로컬개발 지점과 동일하게 병합할 수 있다. 저장소는 Git protocol 및 HTTP로 쉽고 효율적으로 접근할 수 있다.
Strong support for non-linear development
: 신속하고 편리한 branch와 merge를 지원하고, 비선형(여러갈래) 개발 이력을 시각화하고 탐색 할 수 있는 강력한 도구를 제공한다.
Efficient handling of large projects
: Git은 매우 빠르고, 대형프로젝트나 이력이 많은 작업에 매우 합리적이다. 또한, 최근의 정상급 오픈소스 버전관리 시스템보다 장기간의 수정내역을 매우 효율적인 압축방법을 사용한다.
Toolkit design
: UNIX의 전통에 따라, GIT은 C로 작성된 많은 소규모 도구모음이고, 새로운 작업을 위한 손쉬운 사용과 쉬운 스크립팅을 위한 도구를 제공한다.
Git VS Github
GIT : 형상 관리 도구를 사용하면 변경을 쉽게 되돌릴 수 있다. 소스코드를 과거의 특정 시점으로 되돌리거나, 특정 시점의 변경 사항을 취소하거나, 두 버전의 소스 코드를 비교하는 등의 일이 가능하다.
GIT 웹 호스팅 시스템 : 협업하고 있는 코드를 저장할 서버가 필요하다. 버전 관리 시스템을 지원하는 웹호스팅 서비스의 기능을 통해 push, pull, request같은 이벤트에 반응하여 자동으로 작업(배포 등)을 실행하게 할 수 있다.
ex) GitHub, GitLab, BitBucket
Git의 명령어들의 사용 순서
저장소 복제:git clone또는 저장소 선언:git init
Commit할 파일 선택:git add
선택할 파일을 실제로 기록(Commit)한다:git commit
원격 저장소(인터넷)에 업로드:git push
새로 올라온 Commit들 다운로드:git pull
어떤 파일을 Git으로 관리하고 싶으면 Git 저장소가 있어야 합니다. 그래서 제일 처음에는 이미 있던 저장소를 인터넷에서 복제(git clone)해오거나 새로운 폴더를 저장소로 선언(git init)합니다.
그다음부터는 2. 3. 4. 5. 의 반복입니다. 새로 변경한 파일을 git add 명령어로 커밋할 파일을 선택하고 git commit으로 진짜로 하나의 commit으로 만들어 기록합니다. 그리고 그 commit을 다른 사람과 공유하기 위해 인터넷(GitHub에 만들어둔 저장소)에 git push 명령어로 업로드합니다. 만약에 다른 사람이 그 원격 저장소에 어떤 commit을 새로 업로드했다고 하면 git pull 명령어로 자신의 로컬 컴퓨터에 다운로드해서 확인합니다.
일단 Ubuntu에서 자바를 깔고 환경변수 설정해준것도 쉽지 않았지만 고건 나중에 정리해보겠습니당
우선 Pub Sub 프로그램을 실행시키기 위해서 jar 파일을 따로 받아줘야 합니다. 라이브러리 다운하는 방법에는 직접 우분투 웹브라우저에서 다운방법도 있지만, 저는 윈도우에 다운받아 공유폴더를 설정해주고 사용했습니다. 공유폴더 지정해주는것도 쉽지 않았지만 우분투 공유폴더 구글링하면 권한설정, 마운팅 등 방법 나와있습니다.
이 3가지 라이브러리를 일단 받았습니다.
먼저 sub부분의 프로그램을 실행시켜 줍니다.
-cp로 자신의 jar 파일 위치를 설정해주고 컴파일 시켜줍니다.
java -cp .:(jar파일이름1):(jar 파일이름2) Subscribe 로 실행시켜주면 위와같은 결과가 나타납니다.
메시지를 발행하는Producer 에서 Broker 의 Exchange 로 메시지를 전달하면,Binding 이라는 규칙에 의해 연결된 Queue 로 메시지가 복사된다. 메시지를 받아가는Consumer 에서는 브로커의 Queue를 통해 메시지를 받아가서 처리한다.
서비스용 계정생성
우분투에서 웹브라우저를 열고 http://localhost:15672 (Management plugin)로 접속해주면 자신이 설정한 RabbitMQ 계정을 입력하라고 나오고, 관리자로 설정한 계정으로 로그인을 하게되면 RabbitMQ GUI로 접속하게 된다.
상단에 'Admin'이라는 메뉴에서 Users 기능으로 계정을 관리할 수 있다.
Tags : 계정의 권한을 부여한다. Admin, Monitoring, Policymaker, Management, None 이렇게 5가지 종류가 있다. Admin은 말그대로 Rabbitmq를 마음대로 주무를 수 있는 관리자 계정이고 Monitoring은 조회만 가능하다. Policymaker, Management 등등이 있는데 이 문서는 초보용이니 설명은 과감히 생략! 주의 사항으로 계정의 권한을 최소한 Management 로 설정해 주어야 Management Plugin에 접속이 가능하다. Tags 라는 이름 답게 여러개 설정이 가능하다.
Virtual Host : Queue와 계정을 그룹핑 하는 개념이다. 하나의 계정은 여러 Virtual Host을 할당 받을 수 있으며 자신에게 할당된 Virtual Host에 속한 Queue에만 접근이 가능하다.
Exchange 와 Queue 를 연결하는 Bindings
모든 메시지는 Queue 로 직접 전달되지 않고, 반드시Exchange 에서 먼저 받는다.그리고Exchange Type과Binding규칙에 따라 적절한Queue 로 전달된다.아래와 같은 속성을 갖는다.
Name : Exchange 이름
Type : 메시지 전달 방식
Direct Exchange
Fanout Exchange
Topic Exchange
Headers Exchange
Durability : 브로커가 재시작 될 때 남아 있는지 여부(durable,transient)
Auto-delete : 마지막 Queue 연결이 해제되면 삭제
메시지를 보관하는 Queue
Consumer 어플리케이션은 Queue 를 통해 메시지를 가져간다. Queue 는 반드시 미리 정의해야 사용할 수 있다.
Name : queue 이름.amq.로 시작하는 이름은 예약되어 사용할 수 없다.
Durability :durable은 브로커가 재시작 되어도 디스크에 저장되어 남아 있고,transient으로 설정하면 브로커가 재시작 되면 사라진다. 단, Queue 에 저장되는 메시지는 내구성을 갖지 않는다.
Auto delete : 마지막 Consumer 가 구독을 끝내는 경우 자동으로 삭제된다.
Arguments : 메시지 TTL, Max Length 같은 추가 기능을 명시한다.
하나의 연결을 공유하는 Channels
Consumer 어플리케이션에서 Broker 로 많은 연결을 맺는 것은 바람직하지 않다. RabbitMQ는Channel이라는 개념을 통해 하나의 TCP 연결을 공유해서 사용할 수 있는 기능을 제공한다. 하지만 멀티 스레드, 멀티 프로세스를 사용하는 작업에서는 각각 별도의 Channel 을 열고 사용하는 것이 바람직하다.
어플리케이션과 DB가 강하게 결합되어 있어 어플리케이션의 요청&응답 과정에서 DB 서버로의 요청&응답 모두 완료되어야 응답이 가능합니다.따라서 다음과같은 문제가 발생할 수 있습니다.
1. DB의 응답 시간이 길어진다면 어플리케이션 또한 그만큼 응답시간이 길어집니다. 2. DB 장애시 어플리케이션이 동작하지 못합니다. 3. 어플리케이션 입장에서 감당할 수있는 요청 수가 DB에서는 감당 불가능하다면,성능저하나 장애가 발생할 수 있습니다.
메시지 큐(Message Queueing) 란?
메시지 큐는 프로세스 또는 프로그램 인스턴스가 데이터를 서로 교환할 때 사용하는 통신방법 입니다. 더 큰 개념으로는 메시지 지향 미들웨어(Meesage Oriented Middleware: MOM)를 구현한 시스템을 의미합니다. 여기서 MOM은 비동기 메시지를 사용하는 응용 프로그램 간의 데이터 송수신을 말합니다.
Message Queueing은 대용량 데이터를 처리하기 위한 배치 작업이나, 채팅 서비스, 비동기 데이터를 처리할 때 사용합니다. 프로세스 단위로 처리하는 웹 요청이나 일반적인 프로그램을 만들어서 사용하는데 사용자가 많아지거나 데이터가 많아지면 요청에 대한 응답을 기다리는 수가 증가하다가 나중에는 대기 시간이 지연되어서 서비스가 정상적으로 되지 못하는 상황이 오기 때문에 기존에 분산되어 있던 데이터 처리를 한 곳에 집중하면서 메세지 브로커를 두어서 필요한 프로그램에 작업을 분산시키는 방법을 하는 것이 그 목적입니다.
메시지 큐의 장점
비동기(Asynchronous): Queue에 넣기 때문에 나중에 처리할 수 있습니다.
비동조(Decoupling): Appliction과 분리할 수 있습니다. (각 서비스의 연결을 느슨하게 합니다)
탄력성(Resilience): 일부가 실패 시 전체에 영향을 받지 않습니다.
과잉(Redundancy): 실패할 경우 재실행 가능합니다.
보증(Guarantees): 작업이 처리된걸 확인할 수 있습니다.
확장성(Scalable): 다수의 프로세스들이 큐에 메시지를 보낼 수 있습니다.
메시지 큐의 종류
MQ의 종류로는 여러가지가 있는데 Kafka, RabbitMQ, ActiveMQ(JMS)가 대표적입니다. 모두 공통적으로 비동기 통신을 제공하고 보낸 사람과 받는 사람을 분리합니다. 하지만 업무에 따라서 다른 목적을 가지고 있습니다.
# ActiveMQ(JMS)
MOM을 자바에서 지원하는 표준 API입니다. JMS는 다른 자바 애플리케이션들끼리 통신이 가능하지만 다른 MOM의 통신은 불가능합니다. (AMQP, SMTP 같은) ActiveMQ의 JMS 라이브러리를 사용한 자바 애플리케이션들끼리 통신이 가능 하지만 다른 자바 애플리케이션(Non ActiveMQ)의 JMS와는 통신할 수 없습니다.
# RabbitMQ
RabbitMQ는 AMQP(Advanced Message Queuing Protocol)를 구현한 오픈소스 메시지 브로커입니다. AMQP는 MQ를 오픈 소스에 기반한 표준 프로토콜입니다. 프로토콜만 맞다면 다른 AMQP를 사용한 애플리케이션끼리 통신이 가능하고 플러그인을 통해서 SMTP, STOMP 프로토콜과의 확장이 가능합니다.
# Kafka
Apache Kafka는 LinkedIn이 개발하고 Apache Software Foundation에 기부한 오픈 소스 스트림 프로세싱 소프트웨어 플랫폼입니다. 높은 처리량을 요구하는 실시간 데이터 피드 처리나 대기 시간이 짧은 플랫폼을 제공하는 것을 목표로 하며 TCP 기반 프로토콜을 사용합니다. 클러스터를 중심으로 Producer와 Consumer가 데이터를 Push하고 Pull하는 구조를 가집니다.
아파치 재단의 카프카는 pub-sub 모델의 메세지 큐로써, 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산 데이터 스트리밍 플랫폼입니다. 이는 여러 소스에서 데이터 스트림을 처리하고 여러 사용자에게 전달하도록 설계되었습니다. 하루에 1조4천억 건의 메시지를 처리하기 위해 LinkedIn이 개발한 내부 시스템으로 시작했으나, 현재 이는 다양한 기업의 요구사항을 지원하는 애플리케이션을 갖춘 오픈소스 데이터 스트리밍 솔루션이 되었습니다.
Pub-Sub 모델이란?
카프카는 pub-sub(발행/구독) 모델을 사용합니다. pub-sub은 메세지를특정 수신자에게 직접적으로 보내주는 시스템이 아닙니다. publisher는 메세지를 topic을 통해서 카테고리화 하고 분류된 메세지를 받기를 원하는 receiver는 그 해당 topic을 구독(subscribe)함으로써 메세지를 읽어 올 수 있습니다. 즉, publisher는 topic에 대한 정보만 알고 있고, 마찬가지로 subscriber도 topic만 바라봅니다. publisher 와 subscriber는 서로 모르는 상태입니다.
Apache Kafka의 활용
시스템 또는 애플리케이션 간 데이터를 공유하는 스트리밍 데이터 파이프라인에 구현되어 있으며, 해당 데이터를 사용하는 시스템 및 애플리케이션에도 구현되어 있습니다. Apache Kafka는 높은 처리량과 확장성이 반드시 필요한 다양한 활용 사례를 지원합니다. 특정 애플리케이션에서 데이터 공유를 위한 포인트 투 포인트(point-to-point) 통합의 필요성을 최소화하므로 지연 시간을 밀리초 단위로 줄일 수 있습니다. 그러면 사용자는 더 신속하게 데이터를 이용할 수 있으므로, IT 운영과 전자상거래와 같은 실시간 데이터 가용성이 필요한 활용 사례에 유용할 수 있습니다. Apache Kafka는 초당 수백만 개의 데이터 포인트를 처리할 수 있으므로 빅데이터 과제에 매우 적합합니다.
IT 운영 - 웹 사이트, 애플리케이션 및 시스템이 항상 가동되고 성능을 발휘하도록 데이터에 빠르게 액세스해야 합니다. Apache Kafka는 모니터링, 알림 및 보고와 같은 다양한 소스의 데이터 수집, 로그 관리, 웹 사이트 활동 트래킹에 의존하는 IT 운영의 직무 수행에 매우 적합합니다.
사물 인터넷(IoT) - IoT의 가치는 다양한 센서가 생성하는 유용한 데이터에 있습니다. Apache Kafka는 IoT에서 생성될 것으로 예상되는 대규모 데이터를 처리할 수 있도록 확장성을 염두에 두고 설계되었습니다.
전자상거래 - 전자상거래 분야에서 페이지 클릭, 좋아요, 검색, 주문, 장바구니 및 재고와 같은 데이터를 처리하는 데에 활용되고 있습니다.
기본구조
카프카 클러스터 - 메세지를 저장하는 저장소입니다. 하나의 클러스터는 여러개의 브로커(서버)로 이루어져 있고, 데이터를 이동하는데 필요한 핵심 역할을 합니다.
주키퍼 클러스터 - 카프카 클러스터를 관리하는 역할을 합니다.
프로듀서 - 클러스터에 메시지를 보내는 곳이며 메시지를 카프카에 넣는 역할을 합니다.
컨슈머 - 메시지를 카프카 클러스터에서 읽어오는 역할을 합니다.
파티션 - 메세지가 저장되는 물리적인 파일입니다.
토픽 - 카프카에 전달되는 메시지 스트림의 추상화된 개념이며 메세지를 저장하는 단위입니다. 메세지를 구분하는 용도로 사용되며 일종의 파일시스템의 폴더와 유사합니다. 한개의 토픽은 한개 이상의 파티션으로 이루어집니다. 프로듀서는 메세지를 특정 토픽에 저장을 요청하고 컨슈머는 특정 토픽에서 메세지를 읽기를 요청합니다. 프로듀서와 컨슈머는 토픽을 기준으로 메세지를 주고받게 됩니다.
브로커 - 파티션에 저장된 메시지를 파일 시스템에 저장합니다. 이때 만들어지는 파일이 '세그먼트 파일' 입니다.
파티션
파티션은 추가만 가능한 append-only 파일입니다. 각 메세지의 저장 위치를 Offset 이라고 하며, 프로듀서가 카프카에 메세지를 저장하면, 차례대로 Offset 값을 갖게 됩니다. 프로듀서가 저장한 메세지는 맨 뒤에 추가가 되며, 오프셋을 이용해서 컨슈머가 '메시지를 가져간다. 몇 번째 오프셋까지 읽었다, 몇 번째 오프셋부터 읽겠다'는 요청을 할 수 있습니다. 파티션에 저장된 메세지는 삭제되지 않습니다.
여러 파티션과 컨슈머
프로듀서가 특정 토픽에 메시지를 전송하면 기본적으로 여러 파티션에 번갈아가며 전송되어 파티션을 골고루 사용하게 됩니다. 전송 순서가 중요한 메시지의 경우 메시지에 키(Key)값을 할당하고 이 키를 기반으로 특정 파티션에 전송되도록 파티셔너를 작성할 수 있습니다.
컨슈머는 컨슈머 그룹에 속하게 됩니다. 한개의 파티션은 동일 그룹내에서 한개 컨슈머에만 연결이 가능합니다. 동일 컨슈머그룹에 속한 컨슈머들은 한 파티션을 공유할 수 없습니다.
그룹A에 있는 컨슈머 1, 2는 파티션0 이나 파티션1에 연결할 수 있고, 컨슈머 1, 2가 같은 p0이나 p1을 공유할 수 없습니다. 한개의 컨슈머는 한개의 파티션에 연결이 되고, 컨슈머 그룹 기준으로 파티션의 메세지가 순서대로 처리되는 것을 보장해줍니다.
카프카의 고성능
카프카의 토픽에 여러 프로듀서가 동시에 메시지를 전송할 수 있고 카프카 토픽의 메시지를 여러 컨슈머들이 동시에 읽어 갈 수 있습니다. 뿐만 아니라 하나의 프로듀서가 여러 토픽에 메시지를 전송할 수도 있으며, 하나의 컨슈머가 여러 토픽에서 메시지를 읽어 갈 수도 있습니다. 이처럼 다중 프로듀서와 다중 컨슈머를 지원함으로써 다양한 애플리케이션이 데이터를 주고 받을 수 있게 되었으며, 데이터의 생산자/소비자 관계도 유연하게 구성할 수 있게 됩니다.
파티션 파일은 OS가 제공하는 페이지캐시(메모리의 남는 공간)를 사용합니다. 파일 I/O가 실제로는 메모리에서 처리되기 때문에 I/O 속도가 빨라지게 됩니다.
또한, zero copy 특성을 가져 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사하여. 디스크에서 데이터를 읽고 전송하는 속도가 빨라지게 됩니다.
보통의 다른 메세지 서버에서는 브로커에서 메세지를 필터링하거나 재전송하는 일련의 작업이 필요하지만, 브로커가 하지 않고 프로듀서나 컨슈머가 직접하고, 브로커가 하는 일이 비교적 단순하기 때문에 처리속도가 빨라지게 됩니다.
프로듀서에서 묶어서 보내고 컨슈머에서 묶어서 받는 batch 기법을 사용하여 낱개처리시 보다 처리량이 증가하게 됩니다.
카프카는 수평적인 확장이 용이합니다.
그림처럼 시스템 트래픽이 높아지면 브로커를 추가해서클러스터를 확장할 수 있고, 컨슈머 속도가 느려질 경우에는 컨슈머 그룹에 컨슈머를 추가할 수 있습니다.
카프카의 고가용성
카프카는 고가용성(High Availability)을 제공하기 위해 파티션 데이터의 복사본(Replication)을 유지할 수 있습니다. 복제수만큼 파티션의 복제본이 각 브로커에 생성되며 여러 파티션 중에 하나가 리더가되고 나머지가 팔로워가 되어 리더의 변경사항을 따라가기만 합니다. 프로듀서와 컨슈머는 리더를 통해서만 메세지를 처리하게 되는데, 이때 리더가 속한 브로커에 장애가 발생하면 다른 팔로워가 리더로 선정되어 클라이언트 요청을 담당하게 됩니다.