네이글 알고리즘이란?
Nagle 알고리즘은 네트워크를 통해 보내야 하는 패킷 수를 줄여 TCP/IP 네트워크의 효율성을 향상시키는 수단입니다. Nagle 알고리즘은 여러개의 작은 발신 메시지를 결합하여 한 번에 보내는 방식으로 작동합니다. 승인 받지 못한 송신 packet이 있는 한 송신자는 packet 버퍼가 가득 찰 때까지 버퍼링을 유지함에 따라 결과를 한번에 모두 보낼 수 있습니다.
TCP 의 통신 방식은 흔히 알고 있는 3-Way Handshake 방식입니다. 즉, 요청을 위한 ACK, 응답을 위한 SYN+ACK, 응답에 대한 응답을 위한 ACK 패킷이 있습니다.
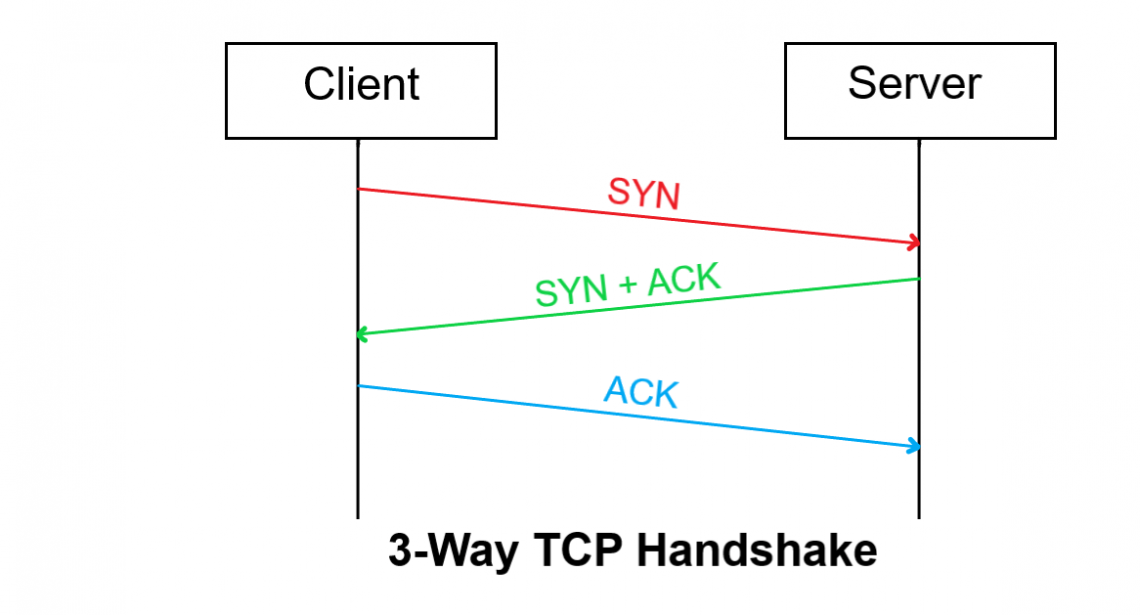
가령, "Hello World" 라는 메시지를 전송해야한다고 가정해봅시다. 어플리케이션이 몇가지 이슈로 인해 H, e, l, l, o, , W, o, r, l, d 와 같이 메시지를 끊어서 보내야한다고 할 때, 이는 TCP 통신에 있어서 커다란 비효율이 됩니다.
TCP 통신을 위해 3-Way handshake 를 거쳐야 하며 이 때 발생하는 주요 문제점은 단순한 메시지의 전달에 대해서도 네트워크 비용이 막대하게 발생한다는 점입니다. 메시지 하나하나의 처리량과 반응속도는 높아질 지언정 전체 "Hello World" 메시지를 통신하기 위해서는 글자수만큼의 네트워크 비용을 소모하게 됩니다.
더군다나 매 통신 시, 컴퓨터는 메시지에 별도의 헤더 등과 같은 추가 정보들을 추가하며 이는 동일한 정보더라도 한 패킷의 사이즈가 커지는 결과를 만들어냅니다. 즉, 하나의 메시지 H 를 보내는데 메시지보다 헤더의 데이터가 더 큰 비효율이 발생할 수 있습니다.
Nagle's Document 에 따라 이러한 문제는 Small Packet Problem 으로 정의되며 Nagle 알고리즘은 이 문제를 해결하는 방법을 제시합니다. Nagle Algorithm 은 송신에 있어서 버퍼를 둔 뒤 상대방 Host 의 Window 사이즈를 고려한 후, 어느정도 길이만큼의 패킷을 한번에 전송하는 기술입니다.
알고리즘


1. 상대방이 받을 수 있는 사이즈(window size)와 전송해야할 데이터가 MSS(최대 세그먼트 크기) 보다 크다면 문제없이 바로 전송
윈도우 사이즈 : 현재 승인되지 않고 허용되는 윈도우 (TCP가 승인없이 전달할 수 있는 사이즈)
MSS : 최대 세그먼트 크기, 연결에서 전송할 수 있는 가장 큰 세그먼트
2. 위 조건에 해당하지 않는다면 전송한 모든 패킷이 승인 될 때까지 버퍼에 모음 (Nagle On)
3. 모든 패킷이 승인되었다면 패킷을 전송

기존의 네트워크 환경에서는 데이터가 버퍼에 조금씩 쌓이게 되면, Nagle off의 그림처럼 상대방의 ACK를 기다리지 않고 바로바로 작은 패킷을 전송하게 되는 반면, 네이글은 이런 작은 패킷을 가능한 지연시키기 위하여, ACK가 올때까지 전송을 중지하고 ACK가 도착한 시점에, 지금까지 버퍼에 모인 데이터를 패킷으로 만들어서 전송합니다.
ACK를 기다리는 지연방식으로 네이글은 작은 패킷을 연속해서 보내는 네트워크의 비효율을 극복하였습니다. 하지만 이런 지연방식을 사용하면 위 그림처럼 같은 기준시간에 데이터 전송속도가 더 늦게 됩니다.
네트워크 게임에서 네이글 알고리즘
게임은 반응성을 중요시합니다. 온라인 게임의 네트워크 상황에서 클라이언트의 경우 서버로 유저의 입력을 전송합니다. 이 입력신호의 경우 데이터 양 자체가 작고, 또 반복적으로 여러 입력이 요청될 수 있기 때문에, 네이글 알고리즘이 작동되기 쉽습니다. 이 입력 패킷이 크기가 작다는 이유로 지연된다면, 사용자의 반응성에 큰 영향을 미치게됩니다. 입력 패킷은 크기는 작아도 게임에 있어 그 의미는 매우 크고 어느정도의 트래픽 효율을 포기하더라도 빠른 반응성을 얻는것이 유저 입장에서도 좋은 거래가 될 것입니다. 따라서 클라이언트 네트워크의 경우에는 네이글 알고리즘을 사용하지 않는 것이 유리하다고 생각합니다.
서버의 경우는 클라이언트와 다릅니다. 서버는 클라이언트에게 현제 유저가 처한 게임 상황의 결과를 지속적으로 보내줄 것이고, 이 정보는 패킷 크기에 비해 헤더 크기가 비대해 보이지 않을 정도로 충분히 큰 양의 데이터일 것이며, 지속적으로 갱신해서 보내주는 데이터가 될 것입니다. 이러한 데이터가 네이글 알고리즘에 의해 지연되는 경우는 클라이언트의 가용 윈도우 사이즈가 충분히 크지 않은 경우가 될 것입니다. 클라이언트의 처리 능력이 원활하지 않은 경우 계속해서 데이터를 잘라서 욱여넣는것이 유저가 체감하는 반응성에 큰 영향을 미칠 것이라 생각하지 않고, 또한 동시에 여러 클라이언트가 사용하는 서버에서 트래픽이슈는 민감한 부분이기 때문에, 네이글 알고리즘을 사용했을때 얻는 이득이 더 클 수 있습니다.
'지식 > 운영체제 및 네트워크' 카테고리의 다른 글
| [운영체제] Mutex 뮤텍스와 Semaphore 세마포어의 차이 (1) | 2021.11.01 |
|---|---|
| [운영체제] IPC 프로세스간 통신 (1) | 2021.11.01 |